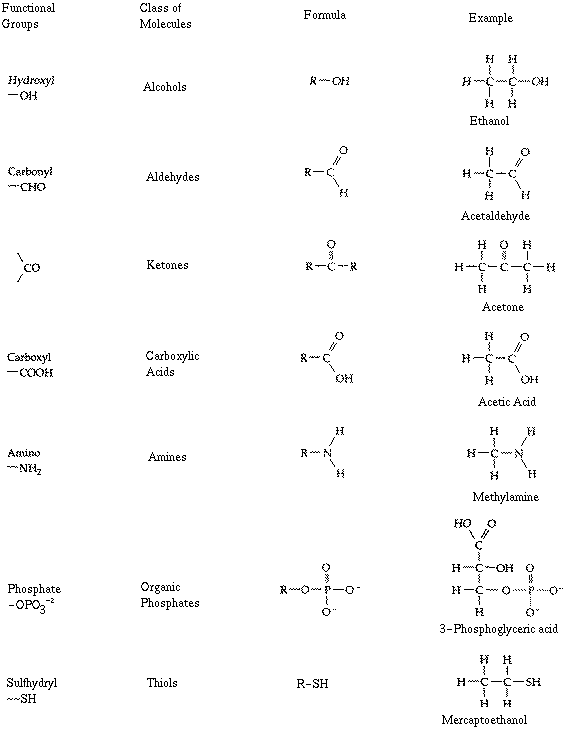
There are a number of functional groups which
are important in the study of biological organisms. They are listed
below.
You should be able to draw the structure
of each of these functional groups without looking them up.
The actual chemicals shown on the right-hand side of the image are for
example - you do not have to know these unless (such as ethanol!)
they are used in class or further down on these web pages.
Hydroxyl
Carbonyl
aldehyde
ketone
Carboxyl
Amino
Phosphate
Sulfhydryl
Shape
All molecules are put together with atoms. Most biological molecules
are constructed primarily from carbon, nitrogen, oxygen and hydrogen, sulfur
and phosphate atoms. Each of these atoms is different:
each forms different numbers
of bonds (the 1,2,3,4 rule)
although it isn't depicted, each atom also has a different size.
For this reason chemicals have shape.
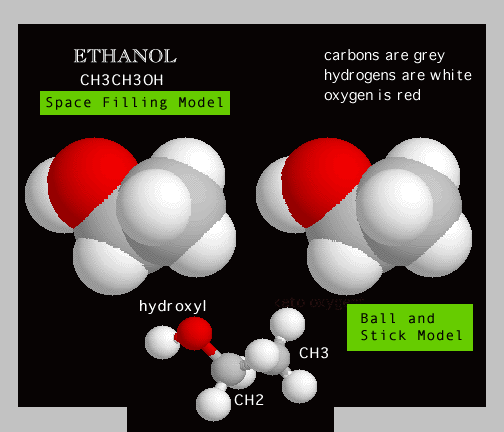
Molecules may be depicted in several ways - as Structural
Formulas, Ball and Stick Models, or Space Filling models.
EXAMPLE: Here is the college male's best friend -
CH3CH2OH
or ......... ETHANOL!
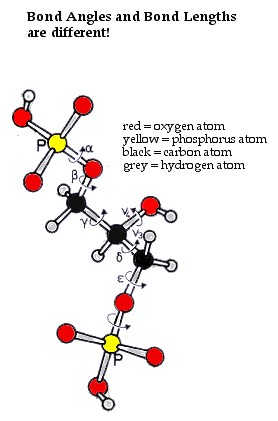
In the Ball and Stick model of Ethanol
notice that the atoms have different numbers of covalent bonds ........
the
carbons have 4 covalent bonds, oxygen has two covalent bonds and the hydrogens
have only 1 covalent bond. Moreover the different kinds
of bonds ( C-O; C-C; C-H; or O-H) have different
bond
angles and different bond lengths!
In the stereoSpace Filling model
of Ethanol note that the SHAPE of Ethanol is the result
of: 1.) different NUMBERS
of bonds formed by each atom; 2,) different BOND
ANGLES formed by each atom; 3.) different BOND
LENGTHS formed by each atom; 4.) different SIZES
of each atom.
3 D models of over 210,000 biomolecules,
drugs, catalysts, toxins and other organic chemicals are available at:
http://www.webmolecules.com
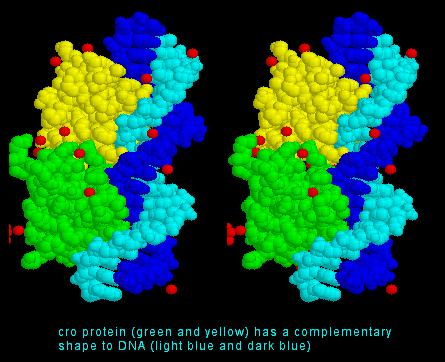
Complementary Fit
Because chemicals have shape they can fit together. This is
the idea of complementary fit.
Examples of complementary fit are:
the ball of the femur and the socket of the pelvis
the piston of an automobile engine and the cylinder in the engine block
a cork and the opening in the neck of a wine bottle
note: none
of these pairs have identical shapes. If they did, they could
not fit together. You cannot plug two electrical plugs together because
they have exactly the same shape. But you can plug them into a wall
outlet which has a very different - but complementary - shape.
The idea that
chemicals have shape, and the corresponding concept of complementary
fit is extremely important in Biology. As we will see
in a short while, it is because molecules have shape that they can fit
together and this enables all of the biological functions which make
life possible.
If complementary fit is not
possible, then life itself often becomes impossible. In fact this
is how many poisons work
- they act by blocking complementary fit between two biological molecules.
It is also the way many drugs
work. For example Acetylsalicylic acid
is
such a drug. It has a structure which can be depicted as a ball
and stick model. The shape of acetylsalicylic acid is
best shown by a stereo space filling model however.
See the story of ASPIRIN.
Another derivative
of Salicylic Acid is Methyl Salicylate,
or Oil of Wintergreen . It is used in liniments and is an
anti-aphrodisiac
in moths
See the
story of Methyl
Salicylate.
A lack of
the proper complementary fit between two molecules is also at the root
of most genetic diseases,
(of course this is why it is necessary to understand chemistry before one
can understand Genetics! ). We will soon study how the concept of
complementary fit explains Albinism, Phenylketonuria
(PKU) and Alkaptonuria.
Solubility
Solubility is another critical property of biological chemicals.
Biological molecules may be water-soluble or water insoluble. Chemists
use 2 greek suffixes to describe these properties: -philia
and -phobia.
-philia means "loving" as used in the following
examples:
bibliophile a lover of books
oenophile a lover of wine
pedophilia erotic desire
for a child
necrophilia erotic desire for a
corpse
coprophilia erotic desire for ..... well,
let's not even get into this one!
hydrophilic
does not mean a desire to have sex in a swimming pool. It
is used by chemists to describe a water loving, or water-soluble molecule.
-phobia means "hating" . Hydrophobic
(water hating) is used by chemists to describe a
molecule which is insoluble in water.
WHY are chemicals
hydrophilic
or hydrophobic? The simple explanation is a
rule that chemists call "Like Dissolves Like".
Water is a highly polar
molecule, because of the electronegativity
of oxygen. Other molecules which are polar like water will be
soluble in water. Some examples
are:
hydroxyl groups
(the oxygen is very electrophilic; the hydrogens are not).
carbonyl groups
(the keto oxygen is very electrophilic).
carboxyl groups
(the carboxylic acid carries a full negative
charge when the acidic hydrogen ionizes).
aldehydes, ketones
and alcohols (the oxygen is very electrophilic).
amino groups
(this base carries a full positive
charge).
N-heterocyclic
rings (the nitrogen is very electrophilic.
Amides
(the nitrogen is very electrophilic).
O-heterocyclic
rings (the oxygen is very electrophilic.
A non-polar
molecule, such as benzene or octane will be insoluble in a polar
molecule such as water, but soluble in other non-polar chemicals. Some
examples
are:
alkanes and alkenes
(the hydrocarbon chains are non-polar).
cyclic hydrocarbons
(the circularized hydrocarbon chains are non-polar).
aromatic hydrocarbons
(the circularized hydrocarbon chains with resonating double bonds are non-polar).
Fats and Oils
(the hydrocarbon chains are non-polar even though one end of these
molecules is a carboxylic acid).
Sugars and Starches
Monosaccharides
Sugars are biological chemical composed of 5 or 6 carbons. Because
of the abundance of hydroxyl groups, sugars are extremely polar
and water-soluble. Two common monosaccharides
are
glucose
and fructose.
Dissacharides
Sucrose and lactose are composed of two
sugars and are therefore termed disaccharides.
note: the linkages
between sucrose and lactose are depicted differently! This is because
there are 2 different ways that sugars can be linked together - a
linkages and b
linkages. We are not going to talk about these linkages in
this course, but they are important in Organic Chemistry and Biochemistry
so you should be aware of them.
Polysaccharides
Polysaccharides.
are long polymers
(chains of chemicals) in which the subunits are sugars.
Amylose and cellulose are examples
of polysaccharides. The only structural difference between them is the
linkage between the glucose molecules, yet the compounds have very different
properties. Amylose (a form of starch)
is water soluble and used by plants as a carbon storage compound. Cellulose
is a tough material found in plant cell walls; it is insoluble in water
and indigestible except by some fungi and protists.
Sugars are important metabolically because they are the major energy storage
molecules for living organisms. Their
carbon rings contain large amounts of energy. For example:
Starch is one of the primary energy storage macromolecules
( a large biological polymeric molecule ) in plants.
Glycogen is also a polymer of glucose and is the primary energy
storage macromolecule in mammals.
Sugars are so important that the way cells "break them down" in order to
extract the energy stored in them is a primary subject of beginning courses
in Biology. Sugars are "broken down" in a long series of chemical
reactions - these chemical reaction are known as Glycolysis, the
Krebs
Cycle, and Oxidative Phosphorylation. Glycolysis
and the Krebs Cycle are examples of biochemical pathways
(
a series of connected chemical reactions).
As we will see
shortly biochemical pathways are also extremely important in Genetics,
because many Genetic Diseases
result when just one of the chemical reactions in a biochemical pathway
does not occur.
Sugars in Nucleic Acids
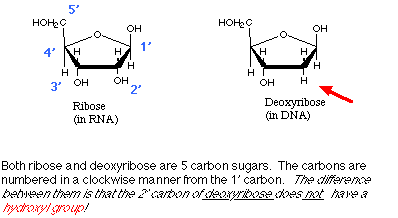
Two other sugars which are extremely important are ribose
and deoxyribose. Ribose
is important because it is one of the structural components of Ribonucleic
Acid (RNA). Deoxyribose is important
because it is one of the structural components of Deoxyribonucleic
Acid (DNA).
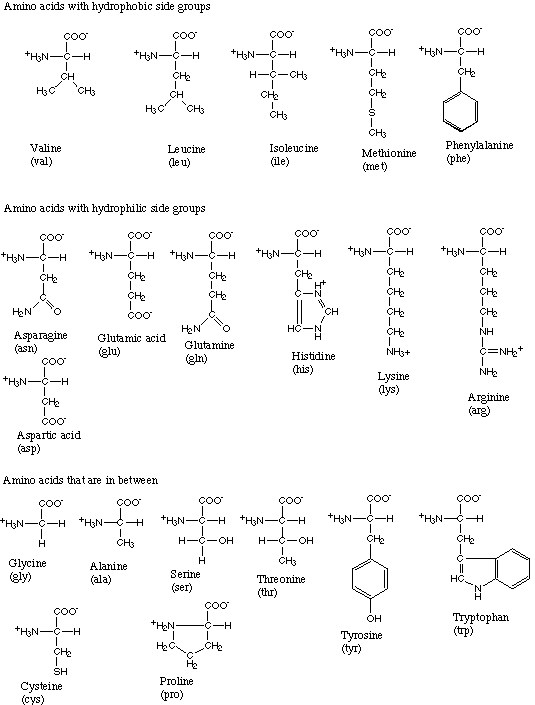
The a
carbon is the central carbon which links each of the 3 groups together.
Every amino acid has the same structure in that it always
has an amino group linked to a carboxyl
group through the a carbon.
However, amino acids have different structures
because the R group (or
side chain) can be any chemical.
Thus there are thousands of possible amino acids. However in biology,
there are only 20 amino acids which are commonly found in proteins.
Therefore there are only 20 amino acids which are fundamentally
important for us.
Since the R groups found in the 20 biologically important
amino acids are each different chemicals, it is to be expected that they
have different chemical properties. In fact the amino acids are usually
classified by the properties of their
side chains:
hydrophilic, positively charged
hydrophilic, negatively charged
hydrophilic, neutral
hydrophobic, neutral
moderate polarity, neutral
Do not memorize each of the different R groups. However you
should study each one carefully, and be able to recognize which
class it fits, and why.
Amino Acids are important because they are the subunits of large biological
molecules ( macromolecules ) called proteins.
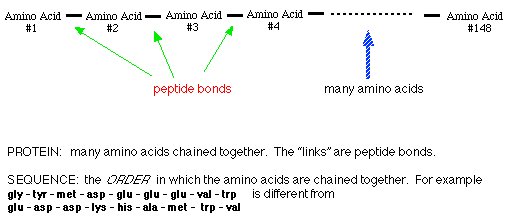
Proteins
(or polypeptides) are chains of amino acids.
An average protein is on the order of 150 amino acids long, although
some are shorter (Insulin), and many are longer.
There are 20
amino acids which commonly occur in proteins.
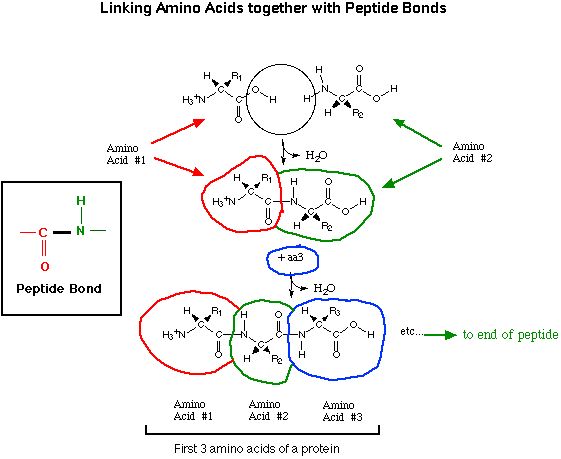
The amino acids are linked together by peptide
bonds through their carboxyl and amino groups.
This chain of amino acids is sometimes referred to as a peptide chain
or a polypeptide.
In an average polypeptide of 150 amino acids, the 1st amino acid could
be any one of 20; the 2nd amino acid could be any one of 20;
the 3rd amino acid could be any one of 20; the 4th amino acid could be
any one of 20; etcetera ..... Since there are over 100 amino
acids in the polypeptide chain ..... and at each position there can be
any one of 20 different amino acids ..... there are millions of different
SEQUENCES
which are possible. For example:
ala-trp-cys-ser-his-trp-trp-gly-glu-ileu
is
one sequence.
ser-his-trp-trp-ala-trp-cys-gly-glu-ileu is
another sequence.
trp-gly-glu-ileu-ala-trp-cys-ser-his-trpis
a third sequence.
The particular sequence
of amino acids which is characteristic of a protein is the Primary
Structure
of that protein.
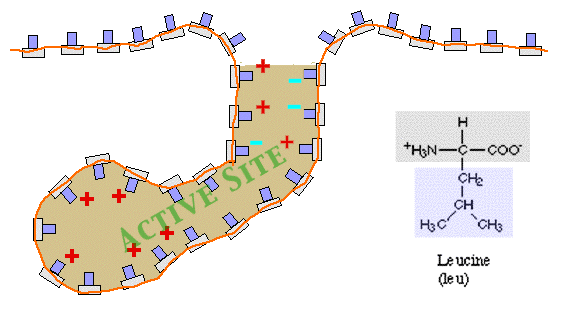
Since amino acids have different R groups (side chains) with different
solubilities (hydrophobic, hydrophilic, in-between) and charges (positive,
negative, neutral), the side chains may interact with each other.
When they do this, the amino acid chain may be bent
into complex and intricate SHAPES!
DeoxyribonucleicAcid
(DNA) is a double-stranded molecule. In other words what we
call a single molecule of DNA is actually composed of 2
single-strands of DNA. Each single strand is a polymer
(a
chain of chemical subunits) in which the subunits are nucleotides.
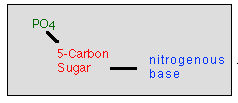
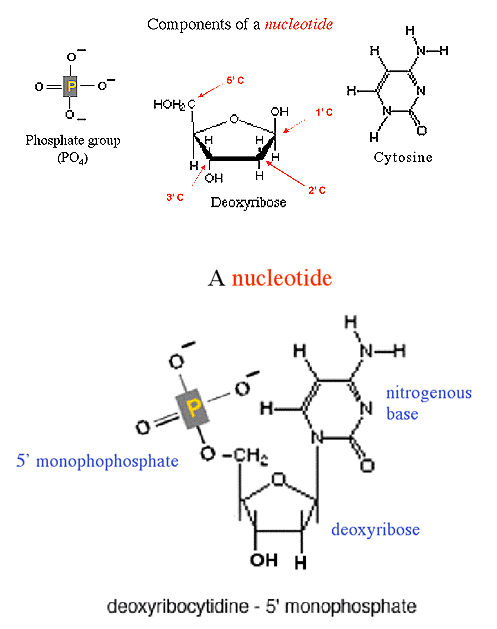
Each nucleotide is composed of 3 smaller chemicals:
deoxyribose sugar Many sugars,
such as glucose, have 6 carbons. But ribose is a 5 carbon
sugar. Deoxyribose, the sugar in DNA, is the cyclic form of ribose deoxygenated
at the 2' carbon.
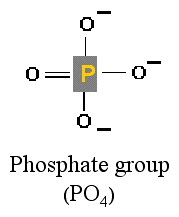
phosphate group This is a molecule
composed of 1 phosphate atom and 4 oxygen
atoms.
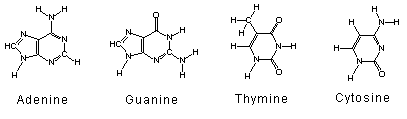
any one of 4 nitrogenous bases A, T, G,
C are N-heterocyclic compounds. They are nitrogenous because they
contain nitrogen atoms. They are a bases because they
are basic chemicals.
These 3 components are linked together
to form a nucleotide. There
are 4
deoxyribonucleotides. A
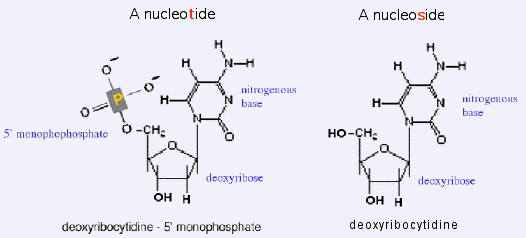
nitrogenous base linked to a deoxyribose - but lacking the 5'
monophosphate - is called a nucleoside.
deoxyriboguanidine
5'-monophosphate
deoxyribothymidine
5'-monophosphate
deoxyribocytidine
5'-monophosphate
deoxyriboadenosine
5'-monophosphate
Do not memorize the structure of the nitrogenous
bases. However you should be able to diagram the structure of the
phosphate group. You should also be able to:
diagram the structure of a deoxyribose
molecule
number the carbons
draw the phosphate group attached
to the correct carbon
given the structure of a nitrogenous
base, draw it attached to the correct carbon
diagram and explain the significance
of the 2' carbon
diagram and explain the significance
of the 3' carbon
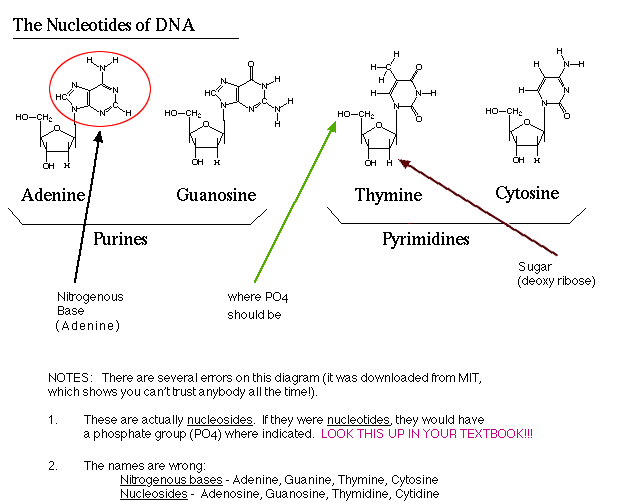
self-test: there
are several *** errors *** in this
diagram
of the 4 nucleotides!! I have left these errors on purpose, so you
can study the structures by learning what is right and what is wrong.
BE
CERTAIN THAT YOU UNDERSTAND!!
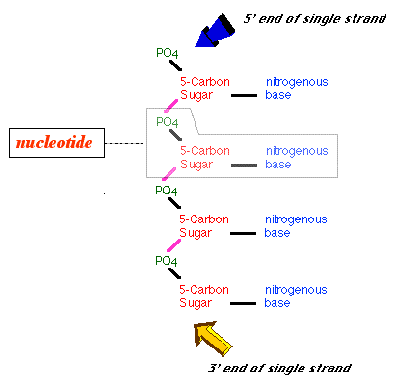
A deoxyribonucleotide is composed of 3 smaller
chemicals. The phosphate is attached to the
5'
carbon of the deoxyribose.
Click on
the image to see it full-size!
The deoxyribonucleotides are chained together
to form a single strand of DNA.
The single strand is held together by a sugar-phosphate
backbone.
The "linker" between the deoxyribose sugars is the phosphate molecule.
The phosphate attached to the5' carbon of each deoxyribose
is linked to the 3' carbon of the
next deoxyribose in the chain by a covalent
bond
(shown in pink).
The result is:
there is a 5' monophosphate at one end of the single strand
there is a free 3' hydroxyl at the other end of the single
strand
THEREFORE a DNA strand has
a 5' endand a 3' end!
Click on
the image to see it full-size!
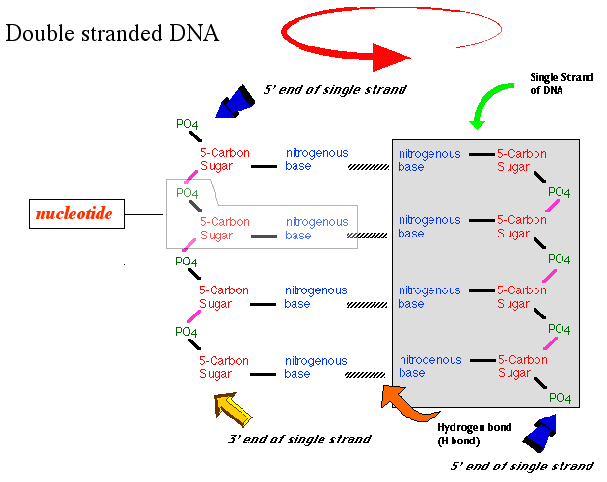
The completedouble-stranded structure
of DNA consists of 2 chains of nucleotides.
The nucleotides in each chain are held together by covalent
bonds between the deoxyribose sugars and the phosphates to form the sugar
phosphate backbone.
The two strands are held together by hydrogen
bonds between the nitrogenous bases of the nucleotides. Hydrogen
bonds can be formed between
Adenine and Thymine base pairs
with 2 hydrogen bonds
Guanine and Cytosine base pairs
with 3 hydrogen bonds
Be able to
diagram
and explain the difference between a covalent bond and a hydrogen
bond!
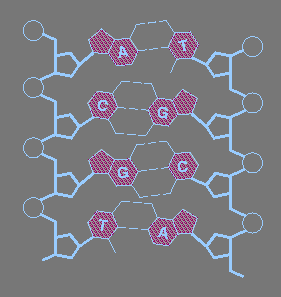
The result is a "ladder" structure in which the sugar-phosphate backbones
form the sides of the ladder and the base pairs form the
rungs.
However a double stranded DNA molecule is not actually shaped like a ladder
as shown in the diagram. It is really twisted into a helix.
Imagine grabbing the ladder which is shown in your right hand. Then
pointing it away from you, twist the top with your left hand
in a clockwise manner. This produces what is known as a right-handed
helix.
NOTE:
The chains run in opposite directions ..... the 5' end of the single strand
on the left is at the top, while the 5' end of the single strand on the
right is at the bottom. This is referred to as anti
parallel.
Here is another
diagram of DNA from MIT. There are several *** errors *** in this diagram.
I
have left these errors on purpose, so you can study DNA by learning
what is right and what is wrong. BE CERTAIN THAT YOU CAN IDENTIFY THE ERROR!!
As
stated above, the 2 strands of DNA twist around each other to form a double
helix. The image to the left shows a ball
and stick model of the 2 sugar-phosphate backbones - one tan, the
other green. If you look carefully, you can see the nitrogenous bases
of each nucleotideprojecting into the center of the helix.
The structure is similar to a staircase in which the base pairs are the
steps.
The image to the right shows shows a space-filling
model of a double-stranded DNA helix. The sugar-phosphate backbone
are in light green. The base pairs are in the center of the helix, depicted
in brown.

 As
stated above, the 2 strands of DNA twist around each other to form a double
helix. The image to the left shows a ball
and stick model of the 2 sugar-phosphate backbones - one tan, the
other green. If you look carefully, you can see the nitrogenous bases
of each nucleotide projecting into the center of the helix.
The structure is similar to a staircase in which the base pairs are the
steps.
As
stated above, the 2 strands of DNA twist around each other to form a double
helix. The image to the left shows a ball
and stick model of the 2 sugar-phosphate backbones - one tan, the
other green. If you look carefully, you can see the nitrogenous bases
of each nucleotide projecting into the center of the helix.
The structure is similar to a staircase in which the base pairs are the
steps.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}