ABSTRACT
In this article we describe an Expert Systems shell to run on the Web. At present, the Web has turned into the most widely dissemination source of knowledge in the whole world. The Experts Systems (ES), which were born to emulate the behaviour of a human expert wherever his knowledge was needed, must be presents on the Web.An Expert System has intelligent information that can't be freely acceded to by the user, instead it must be acceded to by guided navigation. The Web presents the difficulty of being a non connection oriented system and of permitting the free navigation to the user. These problems must be solved so that the ES can control the information flow during a consultation and prevent the initiation of working memory every time a new page is loaded by the browser. Some solutions have been implemented. One of them consists of executing the ES as a cgi program and putting hidden parameters into the HTML code containing the working memory. If the consultation is very long the working memory can reach a considerable volume which would imply the progressive growing of the pages size and the reprocessing by the ES of the same information every time the page is sent to the server. Another solution is to send the complete ES to the user (i.e. as a JAVA applet), but it can take a lot of resources if the knowledge base is too big. Another way is to use files in the server to store the consultation trace which would also involve to initiating the working memory every time we send a web form to the server.
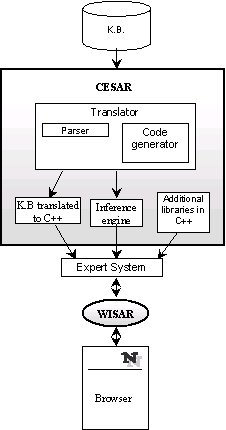
The solution described in this article consists of a shell to create Expert Systems (CESAR) which translates the knowledge base into a C++ program. Each ES is a program which will not be directly called by the user from the Web browser. There is an intermediate process (WISAR, a cgi program) which is called from each page and which communicates the ES with the user. When the ES is consulted, a process is created in the server which remains active during the consultation. From this point the interface module WISAR exchanges information between the ES and the browser (user) using sockets in the server machine. In this way a communication level over the HTTP protocol is established and permits the ES to maintain an open connection during the whole session. This system is multi-user, every time a user asks for a consultation a new ES process is created and run in the server. This solution permits executing a Web application in the server which converses with the user in a similar way as if it were local.
An example of an Expert System developed with this shell is shown in the URL: http://www.lcc.uma.es/cesar/estudios.sar.html.
Keywords: Expert System, Web, Internet, Artificial Intelligence
The objective of the system described in this article is to join the Expert System intelligent knowledge and the capability of the WWW to approach the information to anywhere of the World. One of the reasons to create an Expert System is to put the knowledge of an expert everywhere the expert can't go. The Web is the ideal medium to do that. One of the Web limitations is that it have static information, with this shell programs can be generated which put on the Web intelligent information and adapt the Expert System to the new times.
The system described in this article has three main modules: the knowledge base, the translator (CESAR) and the Web interface (WISAR).
The knowledge base is written using the CESAR (Compiled Extended SAR [Trella, 97]) language. This representation language is based on rules and frames and manages approximated reasoning. The module CESAR is the knowledge base translator. Its function is to analyse the knowledge base content and generate a C++ code which will be compiled and linked with some specific libraries for the processing of expressions and attributes. The result is an executable program (Expert System) ready to be consulted using a Web browser.
The aim of the module WISAR (Web Interface SAR) is to establish the communications and interchange information between the Expert System and the user. It has to offer a consulting interface to the user through Internet. Its inputs and outputs (questions and answers to the user) will be done through Web pages, controlling the data flow between the user and the system (data, error messages, consulting requests...).
2. CESAR, translator and code generator
2.1 Knowledge representation language
A knowledge representation model integrated with rules and frames has been chosen for the realisation of this shell. In this way, the knowledge base will contain the conceptual domain organised as a set of frames (or objects) which are distinguished by their attributes (object properties), and the rules will establish the relations between the different object attributes. The use of frames in the knowledge representation scheme provides a structure to the disordered set of reasoning units of the rules paradigm. Each rule can be associated to the frame that has an attribute which belongs to the rule consequence. This fact provides a partition of the whole rules set, and together with the structure of levels of the frames through the inheritance relation, permits the establishment of a hierarchy in the rules set.
A frame or object is for the shell the fundamental unit of a concept representation that can be a physical element or an abstract category. The object is composed of a name that identifies it and an attribute collection that represents its properties. Each attribute is identified by the value or values set that are assigned to it, the type of these values and the values calculation method. The methods available may be external functions, direct question to the user or rule based interface. All the rules are used to calculate the attribute value that is associated to them. When the calculation method is Console the value attribute is asked directly to the user.
The rules are logic affirmations in the next way:
where P and Q are logic propositions. In the antecedent they can be a trio [object] attribute = value or logic or numerical expressions and in the consequent they can be assignments in the way [object] attribute = expression, where expression can be another trio in the same way or a constant value or a numerical expression. Furthermore, each rule has associated a cf (certainty factor) that is a measure of the belief in the rule affirmation.
The knowledge base objects will be organised following the inheritance relations that exist between them. A superior frame exists and it is the father or predecessor of all the objects in the base. The objects whose first father is this one are called root and the others will be subclasses or instances of other objects defined in the base and will inherit their predecessors attributes. The attributes redefinition is always allowed, and talking about subclasses the new attributes definition is allowed too.
The rules are linked to the frames, so they are affected by the inheritance mechanism. Each rule will be applicable to every object descending of the attribute associated to the rule.
The shell inference engine acts as follows: first it looks for the object in the KB which contains the attribute in the rule consequent. If the attribute has a value this is returned to the user, if not the engine uses the attribute calculation method. In this case the method would be with rules, the back rules inference engine acts over the KB rules.
The syntax of the KB elements described above is:
(NOTE: The original version of this lenguage has reserved words in spanish. We have translated then for this article in order to make it more readable to the english community)
ATTRIBUTE <attributes list>
ATTRIBUTE <attributes list>
ATTRIBUTE <attributes list>
<attribute name> (<type>)[<calculation method>]
<attribute name> (<type>) = <value>
<attribute name> = <value>
where <type> can be:
- NUMERICAL
- INTERVAL
- A discrete values list, in brackets and separated by commas if the attribute is enumerated.
VAR <var>, <var>, ...., <var>
IF <premise> Y
<premise> Y
.......
<premise>
THEN [certainty factor]
[Object1] attribute1 = <expression> Y
.........
[ObjectN] attributeN = <expression>
2.2 Correspondence among a knowledge base elements and C++ objects
The result of a knowledge base translation is a C++ program that, when executed, builds in the memory some data structures that correspond to the structures described in the base. The inference engine, will navigate through those structures that represent the ES working memory. The representation scheme described above is maintained with this implementation and using the C++ capability in the object oriented programming and inheritance.
Each knowledge representation element is translated in the following way:
Root object
| OBJET: <object
name> SUBCLASS OF object
ATTRIBUTE <attributes list> |
| Class
C<object
name> {
Protected:
CAt<type>* <attribute name>;
Public:
Char* name;
|
| OBJET: <object
name> SUBCLASS OF <father name>
ATTRIBUTE <attributes list> |
| Class C<object name>: public C<fathers name> { ... } |
| C<object name>( ):C<father name> ("object name") { ... } |
The attributes that are not inherited and are defined in the subclass, must be translated in the same way as the attributes of a root object.
Object instance
| OBJET: <object
name> IS A <objet instanced name>
ATTRIBUTE <attributes list> |
| C<attribute name> <attribute name>; |
The attributes are translated as a C++ object and are included in the class of the KB frame or instance that they belong. In the add lib, there is a class for each attribute type (Numerical, Interval, Enumerated), that contain all the operators and functions of each type. A derived class of one of this classes are declared for each attribute, for example:
| Class Cat<attribute
name>: public CAttributeNum {
Public: CatLevel (char* v=NULL, float cf=1, char* type="elem1,...."): CAttributeNum (v,cf,type) {}; }; |
The calculate methods are the functions used to calculate an attribute value. Each attribute has a function associated inside the class that it belongs to: this is its calculate method. If the method uses rules, in the function body each rule which has the attribute in the left part of the consequent will be called (the rules are functions too). A value (with a certainty factor) will be assigned to the attribute for each rule that has been satisfied. If the method is console the system will ask the user for the attribute value through a Web form.
Rule
When the inference engine evaluates a rule, it checks all the premises in the antecedent and if all of them are true it assigns the value in the right part of the consequent to the attribute in the left one. Each rule is translated as a global function and its input parameters are the attributes that appear in the rule. The output will be a list with all the attribute values. If any rule has been satisfied the returned value is a null value indicating that the rule is unsatisfied. The translation scheme will be:
| RULE <rule
name>
VAR <var>, <var>, ...., <var> IF <premise> Y <premise> Y ....... <premise> THEN [certainty factor] [Object1] attribute1 = <expression> Y ......... [ObjectN] attributeN = <expression> |
| CatrList*
<rule name> (Cat<atr1 name>,...,Cat<atrN
name>, float cfRule=<cf>)
{ //One cf is calculated for each premise in the antecedent float cf1; .... float cfN; cf1 = <premise1>
if (satisfied(cf1)
&& ... && satisfied (cfN)) {
|
A consultation to an Expert System begins when the user asks for an objective (the value of an attribute in the knowledge base). In some part of the consultation the ES could need to ask the user for the value of an attribute, when he gives the answer, the ES modifies its working memory and stores this value that will be available until the end of the consultation. This process is easy to implement when the user and the system are in the same machine because during the whole session all the answers will be stored in memory.
The most logical way to connect the user and the ES in Internet with this communication scheme is to send a HTML page containing a form to the user every time it needs a value. The user must fill in the form and send it back to the ES. But there is a problem: the HTTP protocol is not connection oriented [NCSA HTTP, 96]. Each time a question is sent to the user the communication line between him and the ES is broken and the ES forgets all the previous connections. Each form that is forwarded to the ES establishes a new connection and the ES begins the execution. The working memory doesn't remain until the next connection.
One solution would be for the ES to use files to store the questions and answers [Bueno, 97], then the working memory would be in a file. In this way, the first task of the ES when is called by the browser would be to read the file and initiate the working memory with the accumulated information.
Another solution to avoid using files, would be to store all the information inside the Web page using hidden parameters [Acquire, 96]. The ES will be a cgi program that will read the page content when it is invoked and will store it in the working memory, it will process all the information and when it needs other data from the user it will generate a Web page with the new question and all the preceding answers. When the page return back to it, it will contain everything as well as the new answer. This process will be repeated until the ES finds the solution to the consultation.
These methods have several inconveniences. The first disadvantage is that the operating way of an ES is lost because a lot of different consultations are done for only one solution. The request is the same each time but modifying the initial working memory state. The second disadvantage is that free data storage in the disk is needed (in the first solution) and file processing time that is not needed in a local consultation. In the second solution the working memory can reach a considerable volume which implies the progressive growing of the pages size and the reprocessing by the ES of the same information every time the page is sent to the server. If the system is small and has a few rules these solutions will be acceptable, but in a large scale system you have to pay a higher cost in time for processing and transferring through the Web.
A different solution is to establish a communication level above the HTTP protocol that would allow the ES to maintain an open connection (without ending the session) while the user gives it an answer, the working memory remaining in the machine memory during the entire consultation. That is the WISAR module mission.
To work on the Internet this system must be multi-user. Each time a new user makes a request a new process (ES) is created with a different process identificator (pid). Each consultation generates a set of auxiliary files, corresponding to the why and how modules that are different for each user. Then, each user executes an independent consultation and does not share data with any other user. This solution has been implemented with a system based on sockets.
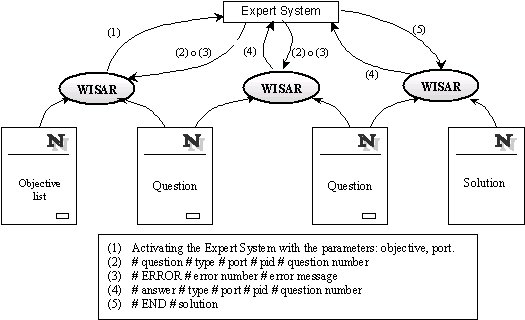
A consultation scheme has been represented in the next figure. The first page seen by a user in his browser is a list with all the objectives available in that system (attributes to ask for). The user chooses one and when he pushes the Accept button the WISAR cgi starts. It sends a call to the server to run the ES with two input parameters; the objective chosen by the user and a port number that WISAR has reserved in the server. The ES begins a consultation and when it finds an attribute whose calculation method is console then that is the moment to ask the user. The way to implement this method is using a procedure that has to send the question to the user and get the answer. This procedure can be implemented like a standard input/output (cin,cout) or like a communication among the process ES and WISAR using sockets.
In the case of CESAR the procedure reserves a port of the system to receive the user's answer, and it send the port number to WISAR with the question and additional information for the errors control. At the same time, WISAR blocks its execution and waits for the instructions of the ES in the reserved port. When an ES question arrives at the port, WISAR reads the data and builds a HTML page, sends it to the browser and finishes its execution. The user fills in the form (answers the question) and pushes the Accept button. At that moment a new process WISAR is started, it reads the contents of the page and sends the answer to the port indicated in the page; after that it waits in another port (reserved at the beginning of the execution and sent to the ES together with the answer) for the ES indications. The ES receives the answer, assigns the value to the attribute and finishes the calculation method. The inference engine continues its job and when it finds other questions for the user the whole process begins again. Once the ES has found a result, it sends it to WISAR (who is waiting in a port) preceded by the string END, closes the last port and finishes its execution. WISAR will send a page with the solution to the browser.
The development of this job has signified the realisation
of an environment for the interpretation of knowledge bases based on rules
and frames, so that the Experts Systems approach the source of knowledge
dissemination most used in the whole world: Internet.
The language used for knowledge base construction
is an extension of the SAR [Molina, 90] language,
its main advantages are that is clear, legible and approaching the natural
language so that any non-expert would be able to understand the knowledge
base content.
Building an Expert System with this shell makes
it possible for it to be consulted in any part of the world and without
having to install any additional software, only the Internet software which
is nowadays installed in all the computers. The user only has to accede
to the server where the ES is installed.
The system is being extended to improve its interface
to be adapted to each domain it manages and to permit the experts to develop
the knowledge base through the Web and all the changes can be seen automatically
at the same time they are done.
Some possible applications of this system would
be to build Experts Systems to do a guided search of information in Internet,
and/or to be used as a Tutorial System support with WWW interface.
| [Molina, 90] | Molina, M. "Proyecto de netorno de representación del conocimiento basado en RULEs y marcos". Dpto. Inteligencia Artificial. Universidad Politécnica de Madrid. |
| [Shortliffe, 84] | Shortliffe, EH y Buchanan, B.G. (1984): "A model of inexact reasoning in Medicine". En Buchanen, B.G y Shortliffe, EH: Rule-Based Expert Systems, Reading, Addison-Wesley. |
| [Acquire, 96] | Acquire Inc (1996), http://vvv.com/ai/demos/whale.html |
| [Bueno, 97] | Bueno, David (1997), http://www.lcc.uma.es/elcastillo |
| [Trella, 97] | Trella, M. (1997) "WWW Shell" Dpto. Lenguajes y Ciencias de la Computación. E.T.S. Ingeniería en Informática. Unicversidad de Málaga. |
| [Stevens, 90] | Stevens, W.R. (1990) "UNIX Network Programming", Prentice-Hall. |
| [NCSA HTTP, 96] | NCS HTTPd Development Team (1996) http://hoohoo.ncsa.uiuc.edu/docs/Overview.html |
Mónica Trella
Computer Engineer
Department of Languages and Computer Sciences
University of Málaga
Address:
Dpto. Lenguajes y Ciencias de la Computación
Campus de Teatinos 29071 MÁLAGA
trella@apolo.lcc.uma.es
http://www.lcc.uma.es/personal/trella/trella.html
Ricardo Conejo
Dr. Ing. Caminos, Canales y Puertos
Department of Languages and Computer Sciences
University of Málaga
conejo@lcc.uma.es
http://www.lcc.uma.es/conejo
Jóse Luis Pérez de la Cruz
Dr. Ing. Caminos, Canales y Puertos
Department of Languages and Computer Sciences
University of Málaga
cruz@apolo.lcc.uma.es
http://www.lcc.uma.es/personal/cruz/perez.html
©, 1997. The authors, Mónica
Trella, Ricardo Conejo,
Jóse Luis Pérez de la Cruz, assign to the University
of New Brunswick and other educational and non-profit institutions a non-exclusive
license to use this document for personal use and in courses of instruction
provided that the article is used in full and this copyright statement
is reproduced. The authors also grant a non-exclusive license to the
University of New Brunswick to publish this document in full on the World
Wide Web and on CD-ROM and in printed form with the conference papers,
and for the document to be published on mirrors on the World Wide Web.
Any other usage is prohibited without the express permission of the authors.